5 Steps to Train Word2vec Model with NodeJS

How to Train Word2vec Model With NodeJS in 5 steps: Introduction
This will be a really short reading about how to get a working word2vec model using NodeJS.
In one of the projects I’ve made in WebbyLab, we had a deal with ML and NLP processing. The main goal was to implement intellectual searches in medical articles. This means not just a simple text match but words similar by meaning. For example, we enter “cancer” and receive “melanoma”, “tumor” etc. Or also perform the search with relations, e.g. we have “cancer” to “treatment” and we search what is in the same relation for “melanoma” – the result should be treatments for it.
Our approach to solve
For such a case, we have decided to use a neural network for the word2vec model based on the worldwide available base of scientific medical articles and their abstracts. Dataset had approximately 100GB of raw XML, which was parsed and normalized to 15GB of plain text. Based on it we have trained the word2vec model step by step.
What is word2vec model
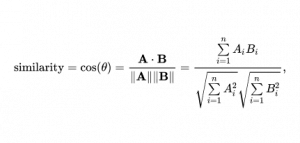
First of all, let’s have a look briefly at what this model stands for. Word vectors (also called word embeddings) are based on a large number of texts — so-called corpus. Each embedding represents the context in which the word appears most frequently. And these vectors are usually many-dimensional (commonly used embeddings are 100 or 300 dimensional but you can use our own custom length). To calculate these embeddings you need to define a so-called “window” which is set before the start of the training. This size means how many words are taken before and after the current word. For example, let’s take a sentence like “I would rather watch youtube than read this article”. In this case, for the word “youtube” words “rather”, “watch”, “than” and “read” will belong to this word window. Using the cosine distance formula you can find similar words (by meaning) which give us the opportunity to perform intellectual searches and not only simple text matching.
Word2vec supports two different algorithms to train vectors: CBOW and skip-gram. In the case of CBOW (Continuous Bag of Words) the algorithm tries to predict the current word based on its context. On the other hand, Skip-gram uses a current word to predict context. Actually, we experimented with both cbow and skip-gram algorithms and the first one sometimes gave more accurate results in similarity searches.
I will not dive deep into how exactly this training part is calculated using a one-hot vector because there are already multiple materials on this topic really well written and explained. If you wish a better understanding of the model please check these few posts with detailed explanations about the model. For example, this article provides a really good vision of what is going on with a rather simple explanation and descriptive step-by-step manual. My post is more about the practical side – I mean how to train the word2vec model with NodeJS and get it to work.
In the beginning, I was trying to run it using the TensorFlow framework and python (of course, today we have tensorflow.js but a year ago we didn’t). On the official site, you can find even a docker container with all installed dependencies needed to run TensorFlow. But with it, I’ve faced performance limitations. After a few tries and fails, we found another option: on npm, there was an out-of-the-box solution that gave us what was needed. It was a package called word2vec which is a Node.js interface to the Google word2vec tool. It’s not so popular (I suppose because not so many people were doing ML on JavaScript). But at the same time, it is well documented and (what is more important) has very good performance as it uses under the hood binary for training and searching. So let’s have a look at what is needed to have it running.
Read Also: How to built AI Chatbot Using JavaScript and ChatScript
Train your AI on “Game of The Thrones” 🙂
Just for fun as an example, I took a widely known book by George R. R. Martin “Game of Thrones” and used it as a training corpus for our javascript word2vec model.
So, here are five steps on How to train word2vec model with NodeJS:
Step 1 – Prepare the corpus npm word2vec
To start, you need to clear your text from any punctuation symbols to leave only words and spaces, also lowercasing all of them. Just simple example of what this function could look like:
Of course, if you will have a bigger amount of training data you will need to cut you text into parts and preprocess them one after another. For this example, reading the whole file and passing it though clearText will work, because all 5 parts of “Game of The thrones” was only about 9.4MB, so I had enough memory to preprocess it as one string. In real examples preparing the dataset for training could be the most time-consuming part. After clearing just write it to another file (in my case cleared file was 8.8M):
Step 2 – Training: word2vec model and NodeJS
Here we start using ‘word2vec’ package. All is needed to provide – corpus file and name of the output file with vectors. As options you can set multiple parameters, for example:
- size – length of vectors, by default 100
- binary – format of output (binary or text), text by default
- window – sets maximal skip length between words, 5 by default
- cbow – use the continuous bag of words model instead of skip-gram
Full list of available parameters and their values you can find in package readme.
In my example, I will use all defaults, but size changed to 300.
After running this code you will receive output with instantly changing progress. When it goes to the end you will get a total count of words in your corpus, vocabulary size and time, wasted to preprocess it. Something like this:
On my small corpus, it took about 17-18 seconds and resulted vectors took a size of 33MB. When we were training 15GB corpus it took us 3-4 hours on a powerful laptop. But time, in this case, grew linearly and current binary did not load in memory all vectors but preprocessed them in a stream. So if you have enough patience and time you will be able to train even on a rather large corpus using this package.
Read Also: Configuration management for Node.js apps
Resulted vectors you can see inside of text version of vectors.txt. Each new line represents a separate word like this:
Step 3 – Similarity search
Now that we have finished training the word2vec model with NodeJS it’s time to try it. To use it you have to load the trained file with vectors using load model w2v.loadModel. Then call model.mostSimilar(word, n) passing word for similarity search and number of neighbours.
Good news: you will have to load it only once on init of your process if you wish to build service for word2vec search. Then you will have the whole model loaded into memory and work with it each time you perform mostSimilar call.
Bad news: it could be rather resource-consuming with big vectors file. For the model which we trained on large 15GB corpus, it was needed to order droplet on DigitalOcean with 12GB of RAM to host it there. As for our example, your laptop/PC RAM will be enough for sure.
This similarity search is based on cosine distance formula. The less this distance is – the closer are the words by meaning.
As you remember I was using “Game of The Thrones” books to train our model. Of course, I realize that we will not get so accurate results as with real training corpus which has gigabytes of training data texts. But we are doing this now just for fun.
So let’s search some heroes from the book. For example lets find out who is related to Arya, because it is one of my favorite characters in the book :). I’ve got next result:
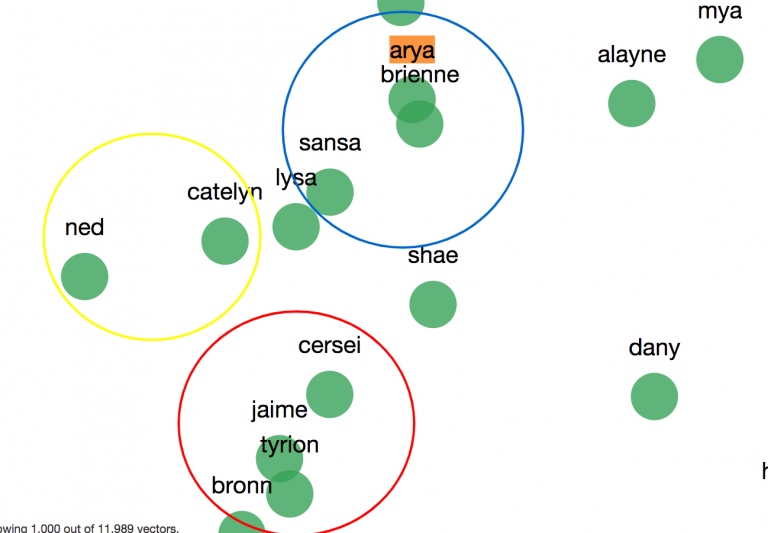
The first three neighbors are sansa, gendry and brienne – actually, all of them were related to Arya in books and HBO TV shows (series and books became a bit different after the second season). Even in a few next results, we have catelyn – her mother, bran – brother and ned – father as well as “dancing teacher” syrio and direwolf nymeria. Not so bad results. Don’t you think so? And all of this we have just after statically analyzing texts.
If we take e.g. four main characters and build graph with relations to them, it will look something like this (I’ve made it for four characters from my choice):
Connect with WebbyLab professionals and turn your ideas into reality
Get a consultationStep 4 – Analogy search
Another useful feature that can be used from the word2vec model is the analogy. For example, if you take a pair Germany – Berlin, the analogy to France should be Paris. Usage of analogy is similar as in the previous example, but you also need to provide a pair as an array of two words:
And let’s search in this case about Daenerys. For the pair, I will choose [ “cercei”, “queen” ].
It means that we ask: If Cercei is queen. Who is Daenerys?
Here is what we’ve got:
So maybe it is not such an accurate result, but at least in the first four entries, we have her different titles: “stormborn”, “targaryen”, “princess” and “unburnt”. Even commonly used in series and books term “khaleesi” and of course “dragons” is somewhere among the nearest results.
Step 5 – Visualize (Optional)
I was searching for a tool for visualization which will be easy-to-use. But I found only a rather old one https://github.com/dominiek/word2vec-explorer and author stopped update it 3 years ago. It will also require to build a model in binary format and install python dependencies:
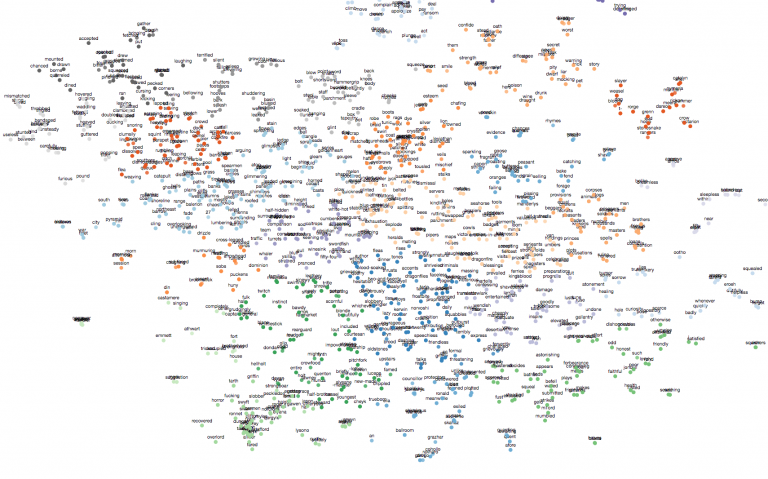
But it made everything that I needed: at least it gives you a user interface for querying similarity and making 2D plots which give us some imagination how this model looks like in space. Here are displayed only 1000 words from 11K vocabulary which we have in Game of The Thrones:
View full size image here.
Even some dependencies between characters can be seen:
And the second interesting mode is ‘compare’ where you can build plot based on 2 words on different axes. Here for example we have Lannisters vs Starks corporation:
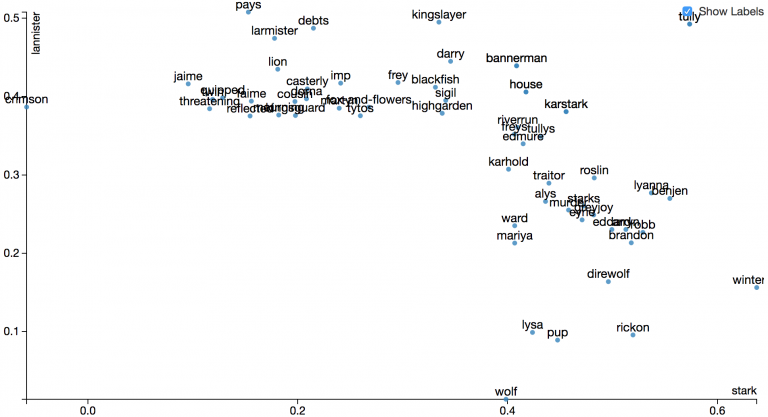
As you see “Lannister pays debts”, ‘cause this phrase meet us frequently during the whole novel 🙂.
What’s next? Try it.
Here we are looking at the end, and you already know how to train word2vec with NodeJS. Feel free to use my code with all examples we have here for the NodeJS part. I’ve made this simple CLI tool that lets you clear, train, search similarities and analogies (by the way, in one of our articles we told a little more about the NPM publish parameters). Here is a description how to use it:
Usage: node cli.js option 1: clear option 2: train from step 1optional, by default will be used 100option 3: similarity for which want find nearest neighborsoptional, amount of neighbors to showoption 4: analogy for which want find analogiesfirst word of the analogy pairsecond word of the analogy pairoptional, amount of analogies to showJavaScript
And everything what we were doing in this post with commands for this CLI (also examples include already trained vectors from my examples so you will be able to use it even without training):
Conclusion
Hope you will enjoy this guide “How to train word2vec model with NodeJS” and will try to use it with your own datasets. Also, you can download already pre-trained vectors from the Glove project – they give pretty accurate results and have a few different sizes which you can choose. What is also good about word2vec is that it really doesn’t depend on language as it just counts vectors based on context. So you can train even using books with Cyrillic languages. I’ve tried the same code with Lev’s Tolstoy “Anna Karenina” as well and managed to get also interesting results even despite the fact that this book is not as large as five parts of Game of Thrones. Have fun using NodeJS to train the word2vec model and pay your debts 😉.
Useful links
- Word2vec NodeJS package on npm: https://www.npmjs.com/package/word2vec
- Manual about how word2vec works: https://towardsdatascience.com/learn-word2vec-by-implementing-it-in-tensorflow-45641adaf2ac
- Vectors from Glove project https://nlp.stanford.edu/projects/glove/
- Other pre-trained vectors: https://github.com/3Top/word2vec-api#where-to-get-a-pretrained-model
- My custom word2vec CLI for running examples from the post https://github.com/unsigned6/word2vec_example
- Similar tool from Facebook for training word embeddings https://fasttext.cc/ and ready-made set of vectors based on Wikipedia – https://fasttext.cc/docs/en/english-vectors.html



Written by:

Yurii Vlasiuk
Technical Lead at 2Smart
Software developer with almost 6 years of experience, interested in smart-home products and learning new technologies
